# Redis 概念
【尚硅谷】Redis 6 入门到精通 超详细 教程 (opens new window)
cV 展示的学习园 (这人笔记写的很好) (opens new window)
Redis(Remote Dictinary Server),C 语言开发,高性能(key-value)数据库, 单线程 + 多路 IO 复用
# Redis 为什么快?
Redis 高性能的核心原因:
- 纯内存操作:所有数据都在内存中,读写速度极快(内存访问速度是磁盘的 10 万倍以上)
- 单线程模型:避免多线程上下文切换和锁竞争,降低 CPU 消耗
- IO 多路复用:使用 epoll/kqueue 等机制,一个线程可以处理多个连接
- 高效的数据结构:SDS、跳表、压缩列表等针对特定场景优化
———— Redis 6.0 引入多线程 IO,但命令执行仍是单线程
# Docker & Redis-Cli
docker run -d --name redis -p 6379:6379 --restart always redis # Aha,顺便设置自启动
docker exec -it redis redis-cli
# Redis-Cli-Test
127.0.0.1:6379> ping
PONG # 看到这个就代表成功了
# Redis 五大数据类型
- String (90%+),二进制安全,最常用
- List,双向链表
- Set,自动去重,字典
- Hash,类似 HashMap,存储键值对
- Zset,有序集合,score(从小到大排列)
# Medis
【Mac】Medis For Redis GUI (opens new window)
【Windows】Another Redis Desktop Manager (opens new window)
# Redis 基本操作
# Key 常用命令
keys *
exists key # 判断key是否存在
del key # 同步删除
unlink key # 异步删除
expire key 10 # 给key设置过期时间,单位是秒
ttl key # time-to-live,查看key还有多久过期,-1永不过期,-2已过期
select 1 # 切换数据库
dbsize # 查看当前数据库keys的数量
flushdb # 清空当前数据库
flushall # 清空所有数据库
# String 常用命令
set k1 111
get k1
mset k1 v1 k2 v2 ...
msetnx k1 v1 k2 v2 ... # 原子性
mget k1 k2 ...
strlen k1 # 获得k1的长度
setnx k1 111 #setnx 只有key不存在时才能成功
getrange k1 1 2 # (java) = k1.substring(1,2)
setrange k1 2 value
setex k1 600 v1 # 同时设置过期时间
getset k1 v2 # 读 & 设置新值
# 以下命令是原子性操作(不会被线程调度机制打断)
incr k1 # +1
decr k1 # -1
incrby k1 10 # +10
decrby k1 10 # -10
# list 常用命令
lpush / rpush k1 v1 k2 v2 ...
lpop / rpop k1 # 东西弹光了key就消失了
rpoplpush k1 k2 # 右弹 + 左插
lrange k1 0 -1 # <start> <stop> , 其中 0 -1 代表取所有值
lindex k1 1
llen k1
linsert k2 before/after k1 "value"
lrem k1 2 "value1" # 从k1左边删除2个value1
lset k1 1 "value2" # 将k1中下标为1的值替换成“value2”
# Set 常用命令
sadd set1 v1 v2 v3
smembers set1
sismember set1 v1 # 判断set1中有无v1这个值
scard set1 # 返回set1中元素个数
srem set1 v1 v2 ... # 删除集合中的元素
spop set1 # 随机从该集合中吐出一个值
srandmember set1 3 # 随机从set1中取出3个值,但不会删除它们
smove k1 k2 v3 # 把v3从k1移到k2中
sinter k1 k2 # 交集
sunion k1 k2 # 并集
sdiff k1 k2 # 差集
# Hash 常用命令
hset user id 611
hset user name liuliyi
hmset user id 1 name liuliyi611 age 24 # 批量设置
hexists user name # user.name 是否存在
hkeys user # 查询user的所有key
hvals user # 查询user的所有value
hgetall user # 一次性查询user的所有内容
hincrby user age 10 # user.age += 10
hsetnx user wife sara # 只有没有此属性,才能设置成功
# ZSet 常用命令
zadd top 100 user1 90 user2 80 user3 # 从小到大排列
zrange top 0 -1
zrange top 0 -1 withscores # withscores 会带上分数一起显示
zrangebyscore top 90 100 # 显示 top 中 90~100 分的
zrangebyscore top 90 100 withscores
ZREVRANGEBYSCORE top 100 80 # 从大到小排列
ZREVRANGEBYSCORE top 100 80 withscores
ZINCRBY top 50 user1 # 给top中的user1加50
ZREM top user
ZCOUNT top 70 100
ZRANK top user2
# Redis 配置文件
配置文件位置:/etc/redis/redis.conf 或 /usr/local/etc/redis.conf
# 面试必知的重要配置项
# ==================================== 网络配置 ====================================
# 绑定 IP,默认只允许本机访问
# 生产环境建议绑定内网 IP 或 0.0.0.0(配合防火墙使用)
bind 127.0.0.1
# 监听端口
port 6379
# 超时时间,0 表示永不超时
timeout 0
# TCP 连接队列长度,高并发场景需要调大
tcp-backlog 511
# ==================================== 内存配置 ====================================
# 最大内存限制,不设置则使用系统全部内存
# 建议设置为系统内存的 50%-70%,为系统留有余量
maxmemory 2gb
# 内存达到上限时的淘汰策略(面试重点)
# volatile-lr: 从已设置过期时间的数据中淘汰最少使用的
# allkeys-lru: 从所有数据中淘汰最少使用的(推荐)
# volatile-lfu: 从已设置过期时间的数据中淘汰使用频率最低的
# allkeys-lfu: 从所有数据中淘汰使用频率最低的
# volatile-random: 随机淘汰已设置过期时间的数据
# allkeys-random: 随机淘汰所有数据
# volatile-ttl: 优先淘汰即将过期的数据
# noeviction: 不淘汰,写入时报错(默认)
maxmemory-policy allkeys-lru
# ==================================== 持久化配置 ====================================
# RDB 持久化策略(多长时间内有多少次变化则保存)
save 900 1 # 900 秒内至少 1 个 key 变化
save 300 10 # 300 秒内至少 10 个 key 变化
save 60 10000 # 60 秒内至少 10000 个 key 变化
# RDB 文件名
dbfilename dump.rdb
# RDB 文件存储目录
dir /var/lib/redis
# 是否压缩 RDB 文件
rdbcompression yes
# RDB 文件校验
rdbchecksum yes
# AOF 持久化开关
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# AOF 持久化策略
# always: 每次写入都同步(最安全,但性能最差)
# everysec: 每秒同步一次(推荐,折中方案)
# no: 由操作系统决定何时同步
appendfsync everysec
# AOF 重写配置
auto-aof-rewrite-percentage 100 # AOF 文件大小比上次重写后增长的百分比
auto-aof-rewrite-min-size 64mb # 触发重写的 AOF 文件最小大小
# ==================================== 性能优化 ====================================
# 最大客户端连接数
maxclients 10000
# 最大并发数,Redis 6.0 引入多线程 IO
# io-threads 4
# io-threads-do-reads yes
# 慢查询日志配置
slowlog-log-slower-than 10000 # 慢查询阈值(微秒),负值禁用慢查询
slowlog-max-len 128 # 慢查询日志最大长度
# ==================================== 安全配置 ====================================
# 密码认证
requirepass yourpassword
# 禁用危险的命令(可重命名)
rename-command FLUSHDB ""
rename-command FLUSHALL ""
rename-command CONFIG "CONFIG_b840fc02d524045429941cc15f59e41cb7be6c52"
# ==================================== 主从复制 ====================================
# 从库配置
replicaof <masterip> <masterport>
# 从库只读
replica-read-only yes
# 主从连接密码
masterauth <master-password>
# 面试高频问题
1. maxmemory-policy 如何选择?
| 场景 | 推荐策略 | 说明 |
|---|---|---|
| 缓存场景 | allkeys-lru/lful | 优先保留热点数据 |
| 会话存储 | volatile-lru | 只淘汰有过期时间的会话 |
| 消息队列 | noeviction | 不允许丢失数据 |
2. RDB 和 AOF 如何选择?
- RDB 优点:文件小、恢复快、对性能影响小
- RDB 缺点:可能丢失最后一次快照后的数据
- AOF 优点:数据更安全、可读性强
- AOF 缺点:文件大、恢复慢、性能影响大
- 生产环境:建议同时开启,Redis 4.0+ 支持混合持久化(RDB + AOF)
3. 为什么建议 appendfsync 设为 everysec?
always:每次写入都刷盘,严重影响性能no:完全依赖操作系统,可能丢失大量数据everysec:每秒刷盘,最多丢失 1 秒数据,性能影响可接受
# Redis 发布 & 订阅
subscribe channel1 # Terminal 1
publish channel1 hello #Terminal 2
# 什么是缓存穿透/击穿/雪崩?如何解决?
# 缓存穿透
定义:查询一个不存在的数据,缓存和数据库都没有,导致每次请求都打到数据库
解决方案:
- 布隆过滤器:将所有可能存在的 key 哈希到一个足够大的 bitmap 中,不存在的 key 直接过滤
- 缓存空对象:当数据库查询为空时,也将该 key 缓存起来(value 为 null),设置较短的过期时间
# 缓存空对象示例
SET user:999 "null" EX 60 # 缓存 60 秒
# 缓存击穿
定义:某个热点 key 过期时,大量并发请求同时访问这个 key,导致数据库压力瞬间激增
解决方案:
- 互斥锁:只让一个请求查询数据库,其他请求等待
- 热点数据永不过期:定期异步更新缓存,不设置过期时间
# 互斥锁示例
SET lock:key "1" NX EX 10 # 获取锁
# 查询数据库...
DEL lock:key # 释放锁
# 缓存雪崩
定义:大量 key 在同一时间集中过期,或者 Redis 宕机,导致大量请求直接打到数据库
解决方案:
- 过期时间加随机值:避免同时过期,
expire time + random(0, 300) - 缓存预热:系统启动时主动加载热点数据
- 限流降级:当缓存失效时,限制请求流量
- 高可用架构:搭建 Redis 哨兵或集群
# 过期时间加随机值(示例)
EXPIRE key 3600 # 基础过期时间 1 小时
EXPIRE key 3750 # +15 分钟随机值
# Redis 新数据类型
Redis6 篇 (三)Redis 新数据类型 (opens new window)
# BitMaps
利用二进制扩展成字符串的方式存储数据,可用于查找用户是否访问过某文章
"abc" = "01100001" + "01100010" + "01100011" = "011000010110001001100011"
SETBIT bitmap1 1 1
GETBIT bitmap1 1 # 1
GETBIT bitmap1 2 # 0
BITCOUNT bitmap1 # 计算bitmap1.count(下标=1)
BITCOUNT bitmap1 [start] [end] # 可以自定义count范围,其中-1代表倒数第一位,-2是倒数第二位,以此类推
对于亿级用户来说,使用 Bitmaps 能节省很多的内存空间,但数量很少的情况下适得其反
# HyperLogLog
是用来做基数统计(去重后的元素个数)的算法
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
pfadd HLL1 "test1" "test2" "test3" "test1"
pfcount HLL1 # 3
pfadd HLL2 "test2" "test3" "test4"
pfcount HLL2 # 3
pfmerge HLL3 HLL1 HLL2 # 把HLL1和HLL2合并成HLL3
pfcount HLL3 # 4
HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
# Geospatial
Redis 3.2 中增加了对 GEO 类型的支持。GEO,Geographic,地理信息的缩写,在地图上就是经纬度。
redis 基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度 Hash 等常见操作。
127.0.0.1:6379> geoadd city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd city 106.50 29.53 chongqing
(integer) 1
127.0.0.1:6379> GEOPOS city shanghai
1) 1) "121.47000163793563843"
2) "31.22999903975783553"
127.0.0.1:6379> GEOPOS city chongqing
1) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> GEODIST city shanghai chongqing
"1447673.6920"
127.0.0.1:6379> GEORADIUS city 110 30 1000 km
1) "chongqing"
# Redis 事务操作
# 事务的概述
- Redis 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。
- 事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
# Multi、Exec、discard
- 从输入 Multi 命令开始,输入的命令都会依次进入命令队列中,但不会执行
- 直到输入 Exec 后,Redis 会将之前的命令队列中的命令依次执行
- 组队的过程中可以通过 discard
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> flushdb
QUEUED
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> SET k3 v3
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) OK
3) OK
4) OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> del k1
QUEUED
127.0.0.1:6379(TX)> del k2
QUEUED
127.0.0.1:6379(TX)> del k3
QUEUED
127.0.0.1:6379(TX)> discard # discard后上述命令全部失效
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
# 事务的错误处理
- 组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消
- 如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> del k1 # 这句执行了
QUEUED
127.0.0.1:6379(TX)> del k2 # 这句执行了
QUEUED
127.0.0.1:6379(TX)> incr k3 # 这句没执行
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 1
2) (integer) 1
3) (error) ERR value is not an integer or out of range
127.0.0.1:6379> keys *
1) "k3"
# 乐观锁 & 悲观锁
- 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis 就是利用这种 check-and-set 机制实现事务的。
- 悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 block 直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
# WATCH
- 在执行 multi 之前,先执行 watch key1 [key2],可以监视一个(或多个) key
- 如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
127.0.0.1:6379> get k1
"120"
127.0.0.1:6379> watch k1 # 监视 k1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> incrby k1 123
QUEUED
######### 另一个终端窗口
127.0.0.1:6379> set k1 111 # 修改了 k1
OK
#########
127.0.0.1:6379(TX)> exec
(nil) # 在开启事务的时候,在执行前先修改一下信息,就会执行失败,这是watch key的作用
# UNWATCH
- 取消 WATCH 命令对所有 key 的监视。
- 如果在执行 WATCH 命令之后,EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了
# Redis 持久化
# Redis 持久化机制有哪些?
Redis6 篇 (六)Redis 持久化 (opens new window)
RDB = Redis Database = 在指定的时间间隔内将内存中的数据集快照 snapshot 写入到磁盘中
AOF = Append Only File = 以日志形式记录每一个写操作(只许追加不可改写)
| 特性 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时快照 | 记录每个写操作 |
| 文件大小 | 小(二进制压缩) | 大(日志文本) |
| 恢复速度 | 快 | 慢 |
| 数据完整性 | 可能丢失最后一次快照后的数据 | 最多丢失 1 秒数据 |
| 性能影响 | fork 子进程,有瞬间阻塞 | 每秒刷盘,持续 IO |
| 适用场景 | 备份、灾难恢复 | 数据完整性要求高 |
# Redis AOF/ RDB 的区别和选择
- RDB 持久化
- RDB 持久化是将 Redis 中的数据保存到磁盘中的一种方式。当配置了 RDB 持久化后,Redis 会定期将内存中的数据快照写入到磁盘中,形成一个 RDB 文件。RDB 文件是一个二进制文件,包含了 Redis 在某个时间点上的所有数据,可以用于恢复 Redis 的数据。
RDB 持久化的优点是占用空间小,数据恢复速度快,适合于备份和灾难恢复。缺点是在持久化过程中可能会丢失一些数据,因为它只能定期将数据快照写入磁盘,如果在快照写入磁盘之前 Redis 发生了崩溃,那么内存中未保存到磁盘的数据将会丢失。
- AOF 持久化
- AOF 持久化是将 Redis 中的操作记录保存到磁盘中的一种方式。当配置了 AOF 持久化后,Redis 会将每个写入命令追加到一个文件中,称为 AOF 文件。AOF 文件是一个文本文件,包含了 Redis 所有的写入操作,可以用于恢复 Redis 的数据。
AOF 持久化的优点是可以保证数据的完整性和一致性,因为它会记录每个写入操作。缺点是占用空间大,恢复速度较慢,适合于数据重要性较高的应用场景。另外,由于 AOF 文件中记录了所有的写入操作,如果写入操作非常频繁,AOF 文件可能会变得非常大,影响性能。
综上所述,RDB 持久化适合于数据量较大、写入操作不频繁、数据恢复速度要求较高的场景,而 AOF 持久化适合于数据重要性较高、写入操作较为频繁的场景。可以根据实际的业务需求选择适合自己的持久化方式。
官方推荐两个都启用。 如果对数据不敏感,可以选单独用 RDB。不建议单独用 AOF,因为可能会出现 Bug。如果只是做纯内存缓存,可以都不用。
RDB 持久化方式能够在指定的时间间隔能对你的数据进行快照存储
AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF 命令以 redis 协议追加保存每次写的操作到文件末尾.
Redis 还能对 AOF 文件进行后台重写,使得 AOF 文件的体积不至于过大
如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
# 性能建议
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
如果使用AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。
代价,一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。
只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。
默认超过原大小100%大小时重写可以改到适当的数值。
————————————————
版权声明:本文为CSDN博主「cv展示」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_45408390/article/details/119731077
# Redis 的过期策略和内存淘汰算法
# 过期策略
| 策略 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 定时删除 | 创建定时器,key 过期时立即删除 | 内存释放及时 | CPU 开销大 |
| 惰性删除 | key 过期不处理,访问时检查并删除 | CPU 开销小 | 内存浪费 |
| 定期删除 | 每隔一段时间随机抽查删除过期 key | 折中方案 | 可能删除不及时 |
———— Redis 采用 惰性删除 + 定期删除 组合策略
# 内存淘汰算法
当内存达到 maxmemory 限制时,触发内存淘汰:
| 算法 | 说明 | 适用场景 |
|---|---|---|
| noeviction | 不淘汰,写入报错 | 不允许丢失数据 |
| allkeys-lru | 所有 key 中删除最少使用的 | 推荐,通用场景 |
| allkeys-lfu | 删除使用频率最低的 | 4.0+,适合热点数据 |
| volatile-lru | 过期 key 中删除最少使用的 | 只淘汰有过期时间的 key |
| volatile-lfu | 过期 key 中删除频率最低的 | 4.0+ |
| allkeys-random | 随机删除 | 很少使用 |
| volatile-random | 随机删除过期 key | 很少使用 |
| volatile-ttl | 删除即将过期的 key | 按过期时间排序 |
# 配置内存淘汰策略
maxmemory 2gb
maxmemory-policy allkeys-lru
# Redis 主从复制 + Redis 集群
Redis6 篇 (七)Redis 主从复制 + Redis 集群 (opens new window)
Redis.conf 原文件 + 配置详解 (opens new window)
# 搭建主从复制
Error: No such file or directory @ rb_sysopen (缺少某库的解决方法) (opens new window)
brew install ca-certificates # 看报错,少什么brew
mac brew 安装 redis (mac 本地安装 redis,便于操作) (opens new window)
brew install redis
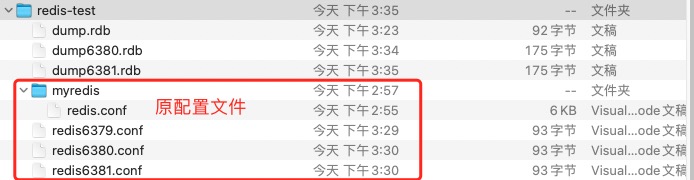
###################### redis6379.conf #######################
include myredis/redis.conf # 测试中没使用绝对路径,否则前面增加‘/’
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
###################### redis6380.conf #######################
include myredis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
###################### redis6381.conf #######################
include myredis/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
liuliyi@liuliyideMacBook-Pro redis-test % redis-server redis6379.conf
liuliyi@liuliyideMacBook-Pro redis-test % redis-server redis6380.conf
liuliyi@liuliyideMacBook-Pro redis-test % redis-server redis6381.conf
liuliyi@liuliyideMacBook-Pro redis-test % ps -ef | grep redis
501 8617 1 0 3:23下午 ?? 0:00.63 /opt/homebrew/opt/redis/bin/redis-server 127.0.0.1:6379
501 8685 1 0 3:30下午 ?? 0:00.51 redis-server 127.0.0.1:6380
501 8687 1 0 3:30下午 ?? 0:00.50 redis-server 127.0.0.1:6381
501 8841 3363 0 3:32下午 ttys001 0:00.00 grep redis
liuliyi@liuliyideMacBook-Pro redis-test % redis-cli -p 6379 # 进入指定端口的redis服务
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0 # 现在没有附属机
master_failover_state:no-failover
master_replid:e44ac240b5de658e4541aa0bddf6645325214997
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
liuliyi@liuliyideMacBook-Pro redis-test % redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 设置主人为6379
OK
liuliyi@liuliyideMacBook-Pro redis-test % redis-cli -p 6381
127.0.0.1:6381> slaveof 127.0.0.1 6379
OK
liuliyi@liuliyideMacBook-Pro redis-test % redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 # 有两台从机了
slave0:ip=127.0.0.1,port=6380,state=online,offset=28,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=28,lag=1
master_failover_state:no-failover
master_replid:0146ab97e819f0c04303677fc70f451a3f1aa244
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28
Q & A
- 从机会【全量】复制主机的内容
- 在主机上写,在从机上可以读取数据,在从机上写数据报错
- 主机挂掉,重启就行,一切如初,从机重启需重设:slaveof 127.0.0.1 6379
- 主机 shutdown 后,从机原地待命,等待主机重新启动,一切回复正常
复制原理
- Slave 启动成功连接到 master 后会发送一个 sync 命令
- Master 接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master 将传送整个数据文件到 slave,以完成一次完全同步
- 全量复制:而 slave 服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给 slave,完成同步
- 但是只要是重新连接 master,一次完全同步(全量复制)将被自动执行
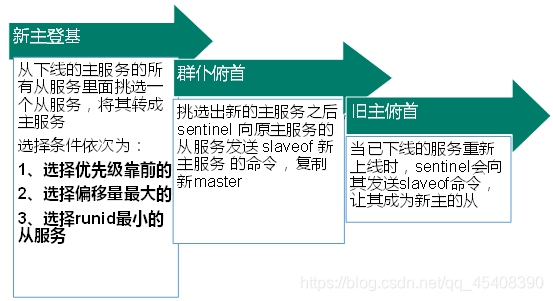
# 反客为主
从机也可以有从机,还可以在主机挂掉的时候反客为主
slaveof no one # 反客为主
# 哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
先搭建一主二从的环境,自定义的/myredis 目录下新建 sentinel.conf 文件
###################### sentinel.conf #######################
# 其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。
sentinel monitor mymaster 127.0.0.1 6379 1
# Redis 集群
集群之前遇到的问题
- 容量不够,redis 如何进行扩容?
- 并发写操作, redis 如何分摊?
- 主从模式,薪火相传模式,主机宕机,导致 ip 地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
redis3.0 中提供了解决方案。就是无中心化集群配置。
# 集群概述
Redis 集群实现了对 Redis 的水平扩容
即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability)
即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
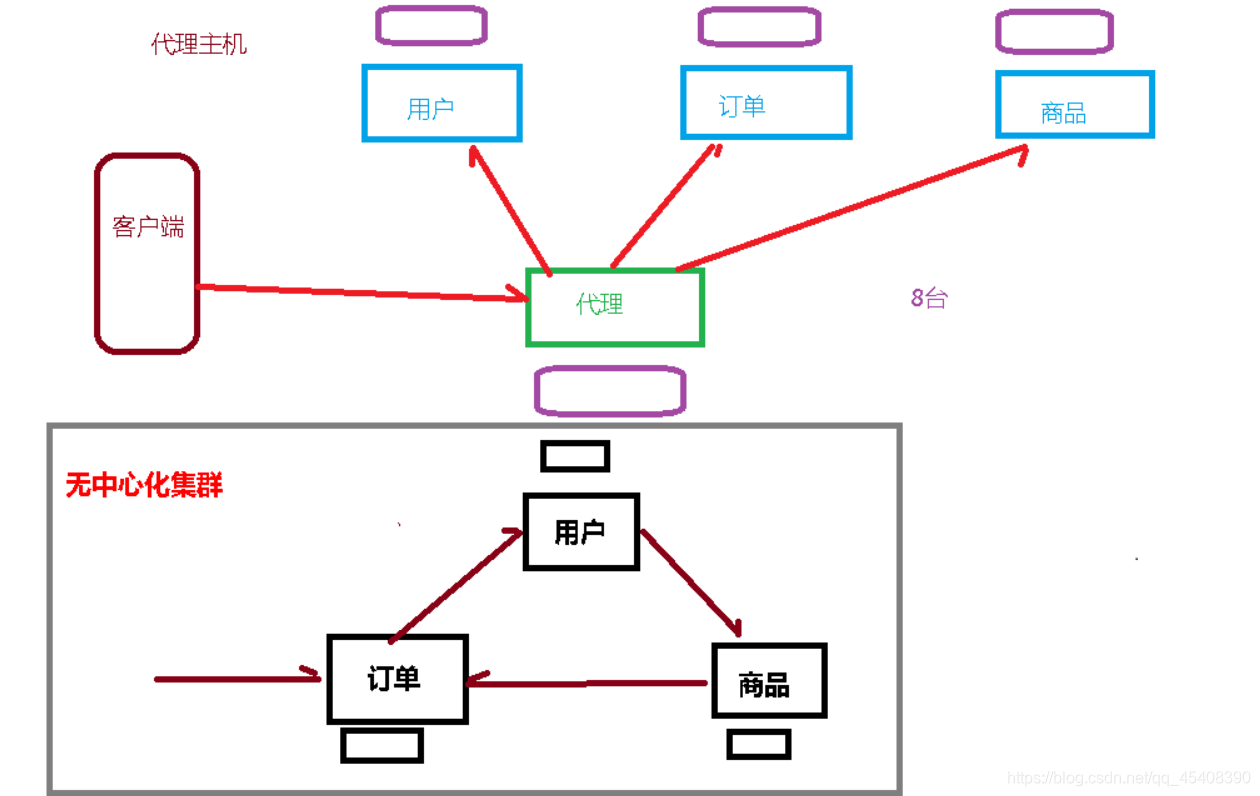
总结:Redis 部署的四种模式
- 单机模式 💻
- 主从模式 💻 - 💻 - 💻
- 哨兵模式 🪖 - ?>> 💻
- 集群模式 💻💻💻💻💻💻 !>> 💻
具体命令点击查看,没往下写了 (opens new window)
# 多实例情况下,怎么通过 redis 防止定时任务多次执行?
在多实例情况下,可以使用 Redis 分布式锁来防止定时任务多次执行。
1.在执行定时任务之前,使用 Redis 的 SETNX 命令尝试获取锁。如果获取成功,说明该实例获得了锁,可以执行定时任务。
2.在执行完定时任务之后,使用 Redis 的 DEL 命令释放锁。
3.如果获取锁失败,说明其他实例已经获得了锁,该实例应该等待其他实例释放锁。
代码示例:
const Redis = require('ioredis');
const redis = new Redis();
const taskName = 'myTask';
const lockTTL = 60; // lock expires in 60 seconds
async function runTask() {
// try to acquire lock
const lockAcquired = await redis.setnx(taskName, 1);
if (!lockAcquired) {
console.log('Task already running, exiting...');
return;
}
// set lock expiration
await redis.expire(taskName, lockTTL);
try {
// perform task
console.log('Running task...');
// ...
} finally {
// release lock
await redis.del(taskName);
}
}
这样可以确保一次只有一个实例在执行定时任务,避免了多次执行的问题。
需要注意的是使用 Redis 分布式锁时,要尽量避免死锁的情况,如果锁被占用过长可以在超时时间后自动释放锁或者人工释放。
# 计划任务时间大于轮询时间时怎么处理?
# 双重缓存
使用两个 Redis Key 来管理任务状态:
- 状态缓存:标记任务是否正在执行(设置过期时间为轮询时间的 2-3 倍)
- 数据缓存:存储任务执行的结果或中间数据
工作原理:
async function scheduledTaskWithDoubleCache() {
const statusKey = 'task:status';
const dataKey = 'task:data';
const pollInterval = 60; // 轮询间隔 60 秒
const taskTimeout = 300; // 任务超时时间 5 分钟
// 1. 检查状态缓存
const isRunning = await redis.get(statusKey);
if (isRunning) {
console.log('任务正在执行中,跳过本次轮询');
// 可选:读取数据缓存,获取任务进度
const progress = await redis.get(dataKey);
console.log('当前进度:', progress);
return;
}
// 2. 设置状态缓存,标记任务开始执行
await redis.setex(statusKey, taskTimeout, 'running');
await redis.set(dataKey, '任务开始执行');
try {
// 3. 执行任务逻辑
await redis.set(dataKey, '任务执行中...');
await performLongRunningTask();
// 4. 保存结果
await redis.set(dataKey, '任务完成');
await redis.setex('task:result', 3600, JSON.stringify(result));
} catch (error) {
await redis.set(dataKey, '任务失败: ' + error.message);
throw error;
} finally {
// 5. 清除状态缓存
await redis.del(statusKey);
}
}
优点:
- 可以追踪任务执行状态和进度
- 避免任务重复执行
- 可以查看历史执行结果
# 缓存续期
在任务执行过程中,定期续期状态缓存的过期时间,防止因任务执行时间过长导致缓存过期。
工作原理:
async function scheduledTaskWithRenewal() {
const statusKey = 'task:status:renewal';
const lockTTL = 60; // 初始锁时间 60 秒
const renewalInterval = 30; // 每 30 秒续期一次
// 1. 尝试获取锁
const lockAcquired = await redis.set(statusKey, '1', 'NX', 'EX', lockTTL);
if (!lockAcquired) {
console.log('任务正在执行,跳过');
return;
}
// 2. 启动续期定时器
let shouldStop = false;
const renewalTimer = setInterval(async () => {
if (!shouldStop) {
// 续期:重新设置过期时间
await redis.expire(statusKey, lockTTL);
console.log('锁续期成功');
}
}, renewalInterval * 1000);
try {
// 3. 执行长时间任务
console.log('开始执行长时间任务...');
await performLongRunningTask();
console.log('任务执行完成');
} catch (error) {
console.error('任务执行失败:', error);
throw error;
} finally {
// 4. 停止续期并释放锁
shouldStop = true;
clearInterval(renewalTimer);
await redis.del(statusKey);
console.log('锁已释放');
}
}
// 使用 Redis Redlock 算法的更安全版本
async function scheduledTaskWithRedlock() {
const statusKey = 'task:status:redlock';
const lockTTL = 30; // 锁的自动释放时间
const renewalInterval = 10; // 续期间隔
const lockId = Date.now().toString(); // 唯一锁标识
const lockAcquired = await redis.set(statusKey, lockId, 'NX', 'EX', lockTTL);
if (!lockAcquired) {
console.log('获取锁失败,任务可能正在执行');
return;
}
let renewing = true;
// 异步续期
const renewalPromise = (async () => {
while (renewing) {
await new Promise(resolve => setTimeout(resolve, renewalInterval * 1000));
// 检查锁是否还是自己持有的(防止误删其他请求的锁)
const currentLock = await redis.get(statusKey);
if (currentLock === lockId) {
await redis.expire(statusKey, lockTTL);
console.log('续期成功');
} else {
console.log('锁已被其他请求持有,停止续期');
break;
}
}
})();
try {
await performLongRunningTask();
} finally {
renewing = false;
// 确保续期线程结束
await renewalPromise;
// 只有锁还属于自己时才释放
const script = `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
`;
await redis.eval(script, 1, statusKey, lockId);
console.log('锁已安全释放');
}
}
关键要点:
- 续期间隔:通常设置为锁 TTL 的 1/3 到 1/2
- 唯一锁标识:使用唯一 ID 防止误删其他请求的锁
- Lua 脚本:保证检查和删除操作的原子性
- 异常处理:确保续期线程在任务结束时正确停止
优点:
- 适应任务执行时间不确定的场景
- 防止因任务超时导致的锁失效
- 即使任务执行时间远超轮询间隔也不会重复执行
# 如何使用 redis 实现简单的消息队列?
要使用 Redis 实现简单的消息队列,你可以借助 Redis 的列表数据结构来实现。
以下是一个基本的示例,展示如何使用 Redis 来创建一个简单的消息队列:
DaoyouLun: 实现消息队列长度为 5
const Redis = require('ioredis');
const client = new Redis(6379, '127.0.0.1');
async function send(msg) {
const cur = await client.llen('test_queue');
console.log(cur); // 设置消息队列上限为5
if (cur > 5) {
console.error('size more than 5');
return;
}
await client.lpush('test_queue', msg);
}
async function poll() {
try {
const message = await client.rpop('test_queue');
if (message) {
console.debug(message);
}
} catch (err) {
console.error(err);
}
process.nextTick(poll);
}
poll();
async function main() {
await send('111');
await send('222');
await send('333');
await send('444');
await send('555');
await send('666');
}
main();
# 用 redis 实现一个分数排行榜,并从中查找前十名的数据
zadd leaderboard 100 PlayerA
zadd leaderboard 80 PlayerB
zadd leaderboard 120 PlayerC
zrevrange leaderboard 0 9 WITHSCORES
const redis = require('ioredis');
const client = redis.createClient();
// 添加成员和分数到排行榜
function addMemberToLeaderboard(member, score) {
client.zadd('leaderboard', score, member, (err, reply) => {
if (err) {
console.error('Failed to add member to leaderboard:', err);
} else {
console.log('Member added to leaderboard:', member);
}
});
}
// 获取排行榜前十名的数据
function getTopTenFromLeaderboard() {
client.zrevrange('leaderboard', 0, 9, 'WITHSCORES', (err, results) => {
if (err) {
console.error('Failed to get top ten from leaderboard:', err);
} else {
console.debug(results);
// [
// 'PlayerL', '123', 'PlayerI',
// '122', 'PlayerF', '121',
// 'PlayerC', '120', 'PlayerJ',
// '103', 'PlayerG', '102',
// 'PlayerD', '101', 'PlayerA',
// '100', 'PlayerK', '83',
// 'PlayerH', '82'
// ]
console.log('Top ten from leaderboard:');
for (let i = 0; i < results.length; i += 2) {
const member = results[i];
const score = results[i + 1];
console.log(`${i / 2 + 1}. Member: ${member}, Score: ${score}`);
}
}
});
}
// 示例添加成员和分数到排行榜
addMemberToLeaderboard('PlayerA', 100);
addMemberToLeaderboard('PlayerB', 80);
addMemberToLeaderboard('PlayerC', 120);
addMemberToLeaderboard('PlayerD', 101);
addMemberToLeaderboard('PlayerE', 81);
addMemberToLeaderboard('PlayerF', 121);
addMemberToLeaderboard('PlayerG', 102);
addMemberToLeaderboard('PlayerH', 82);
addMemberToLeaderboard('PlayerI', 122);
addMemberToLeaderboard('PlayerJ', 103);
addMemberToLeaderboard('PlayerK', 83);
addMemberToLeaderboard('PlayerL', 123);
// 查询排行榜前十名的数据
getTopTenFromLeaderboard();